
根据 OpenAI 指出,GPT-4o mini 不仅性能更强,价格也来到了「白菜价」。具体来讲,GPT-4o mini 每百万个输入 Token 的定价是 15 美分(约合人民币 1.09 元),每百万个输出 Token 的定价是 60 美分(约合人民币 4.36 元):
不过这里还有一个可能存在的误解,尽管 GPT-4o mini 比 GPT-4o 等大模型要小得多,但其规模依然比手机上搭载的端侧大模型(基本不超过 7b)大得多。因此,在 iOS 18 等系统上,GPT-4o mini 还是通过云端而非本地的形式提供服务。
用一个例子来简单说明下,分别询问通过这三个模型询问 ChatGPT:「介绍下 OpenAI 最新发布的 GPT-4o mini 模型。」
在生成结果上,GPT-4o mini 的回答并不包含任何数据,内容相对空洞,但相关描述基本正确。考虑到 OpenAI 指出 GPT-4o mini 只具有截至 2023 年 10 月的知识,且在 ChatGPT 中不支持联网,可以说明 GPT-4o mini 是从命名作出的「推测」。

相比之下,GPT-4(未经联网搜索)告诉我「OpenAI 并没有发布名为『GPT-4o mini』的模型」,直到主动要求联网搜索,才真正开始介绍。不过即便如此,GPT-4 还是没有明显超出 GPT-4o mini 生成的答案,就算明确问它「成本有多低」,也没能给出让人满意的答案。
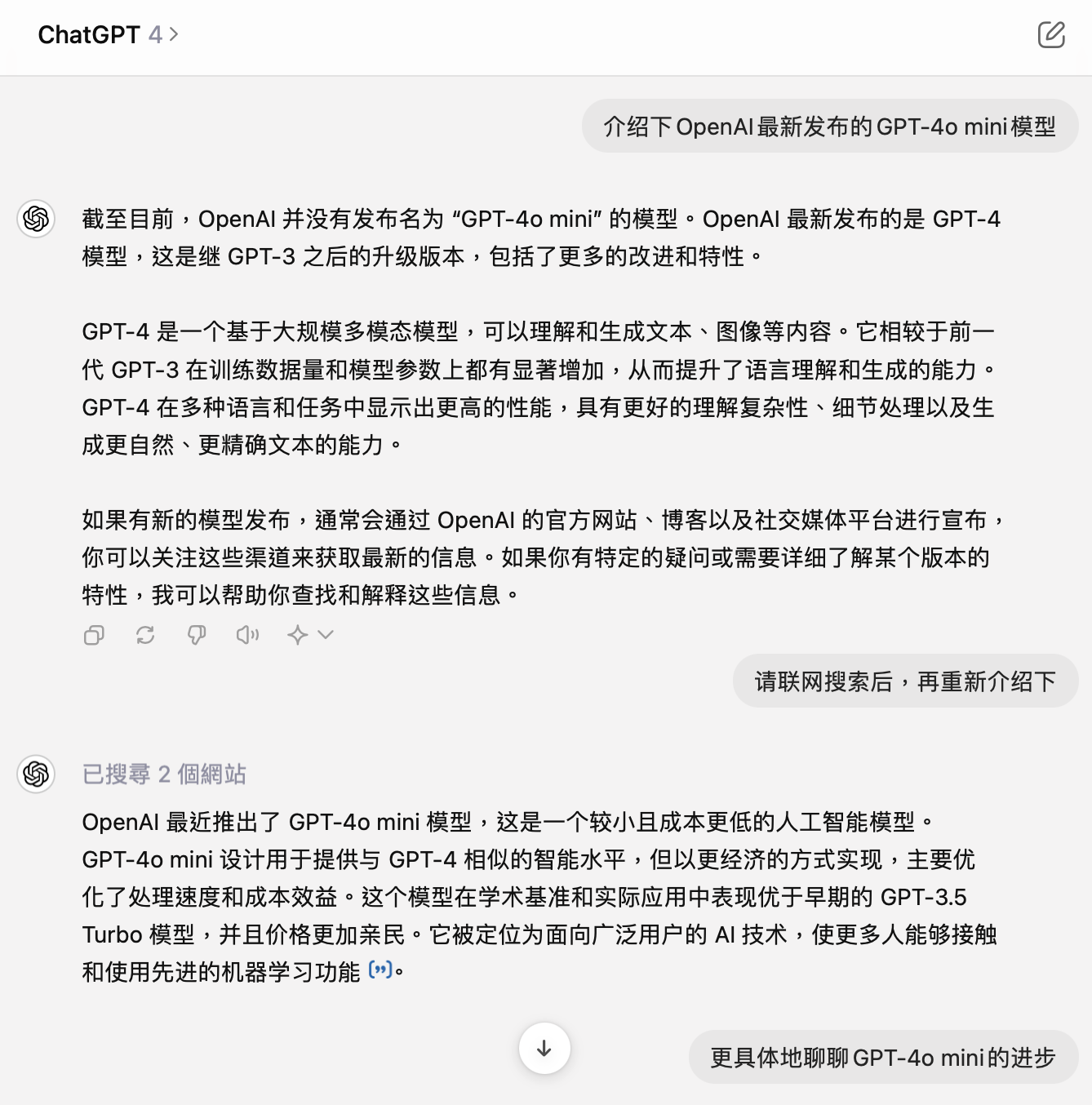
至于 GPT-4o(自动联网搜索),作为目前 OpenAI 旗下甚至全世界最强大的模型,其表现毋庸置疑。更详略得当的介绍、更确凿的数据和引用链接,都让它能够继续稳坐大模型的头把交椅。

简单总结一下,GPT-4o mini 相比之前的 GPT-3.5 有着明显的进步,甚至相比 GPT-4 也有一定优势。虽然我目前的几个简单测试基本符合 OpenAI 和 LMSYS 排行榜给出的结论,但要下最终结论还是太早。如果大家有需求,后续可以做更全面的对比。
另外,OpenAI 也公布 GPT-4o mini 在不同基准下的「跑分成绩」,以供参考:
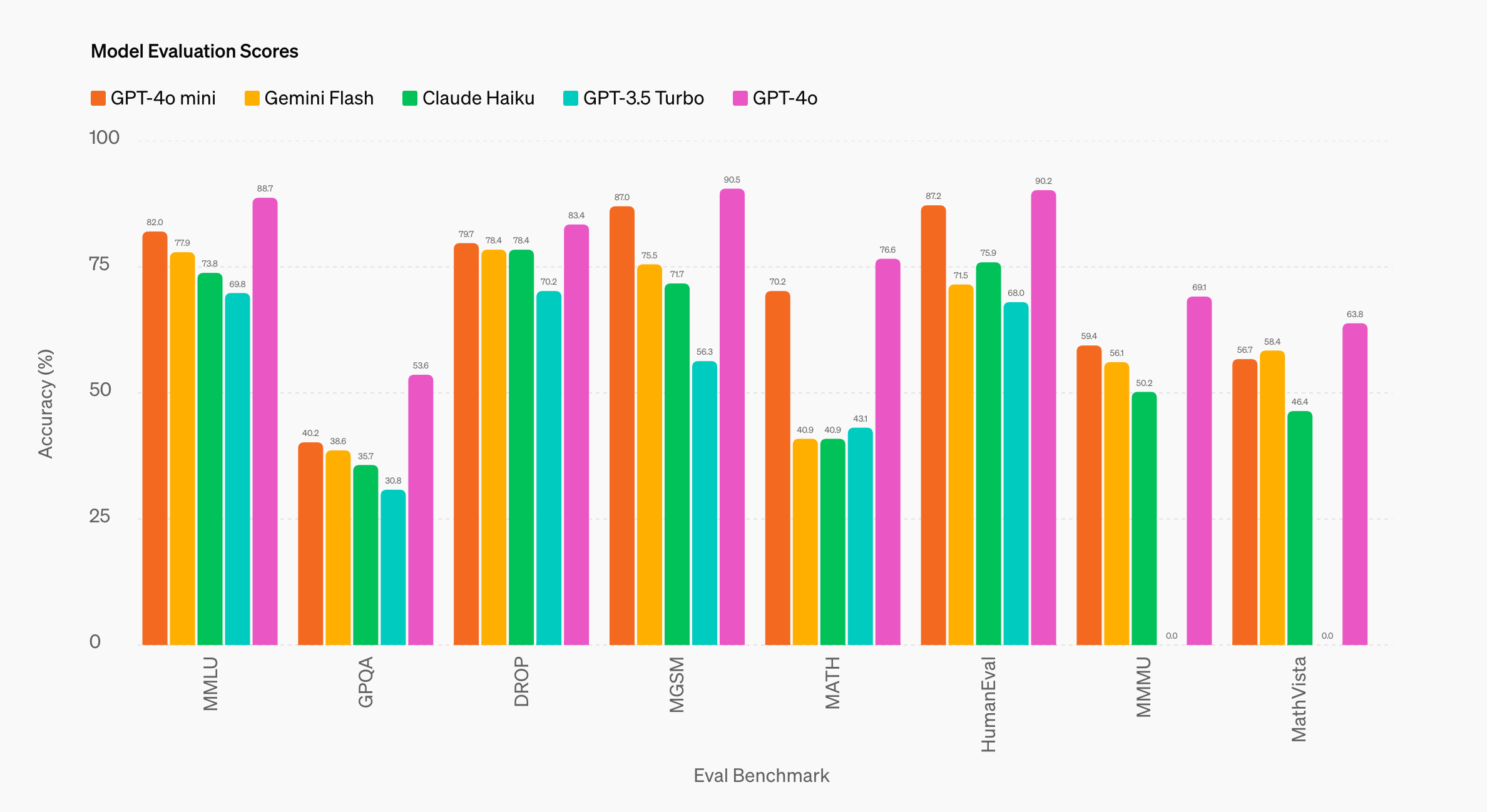
总体来看,相比 Gemini 1.5 Flash、Claude 3 Haiku 这两个同样主打「性价比」的模型(由超大模型衍生),GPT-4o mini 的优势还是显而易见,尤其是在 MGSM(数学推理)、MATH(数学解决)、HumanEval(代码生成)等方面。
同时 OpenAI 还表示,GPT-4o mini 在 API 中支持文本,之后还会逐步增加图像、视频和音频的输入输出支持,且得益于与 GPT-4o 共享的改进 Token 生成器,处理非英语文本现在更加经济高效。
在 GPT-4o mini 推出之后,马上就有海外和国内的开发者计划切换到 GPT-4o mini 试试,比如前爱范儿副总裁兼首席设计官@Ping.开发的 AI 语音笔记 App「闪念贝壳」:
事实上,对于 GPT-4o mini 来说,现阶段最核心也最重要的用户是 API 面向的开发者,而非 ChatGPT 面向的普通用户。
对于 OpenAI 来说,推出 GPT-4o mini 是一件比较反常的事情,因为在此之前,从 GPT-1/2/3、GPT-3.5 到 GPT-4、GPT-4o,OpenAI 都是在推出更强的大模型,冲击机器智能的天花板。就算是 Turbo 系列,也是同等性能下优化速度和成本。
但在 GPT-4o mini 上,OpenAI 选择了缩小模型规模、降低模型性能,以实现更具成本效益的生成式 AI 模型。
对此,Olivier Godement 的解释是,OpenAI 专注于创建更大、更好的模型,如 GPT-4,这需要大量的人力和计算资源。不过跟着时间的推移,OpenAI 注意到研发人员越来越渴望使用较小的模型,因此企业决定投入资源开发 GPT-4o mini,并于现在推出。
「我们的使命是使用最前沿技术,构建最强大、最有用的应用程序,我们当然希望继续做前沿模型,推动技术进步,」Olivier Godement 在采访中说,「但我们也希望拥有最好的小模型,我认为它会非常受欢迎。」

简单来说,就是优先级的问题。但在优先级的背后,是慢慢的变多公司偏好中小型的生成式 AI 模型。
WSJ 近期的一篇报道,就援引多家公司高管以及 Google Cloud 全球生成式 AI 产品上市策略副总裁 Oliver Parker 指出,过去三个月,企业正在集体转向更小参数规模的生成式 AI 模型。
根据 AIGCRank 维护的《国内外 AI 大语言模型 API 价格对比》榜单:
- GPT-4o 每百万个输入 Token 的定价是 5 美元(人民币约为 36.3 元),输出是 15 美元(人民币约为 109 元);
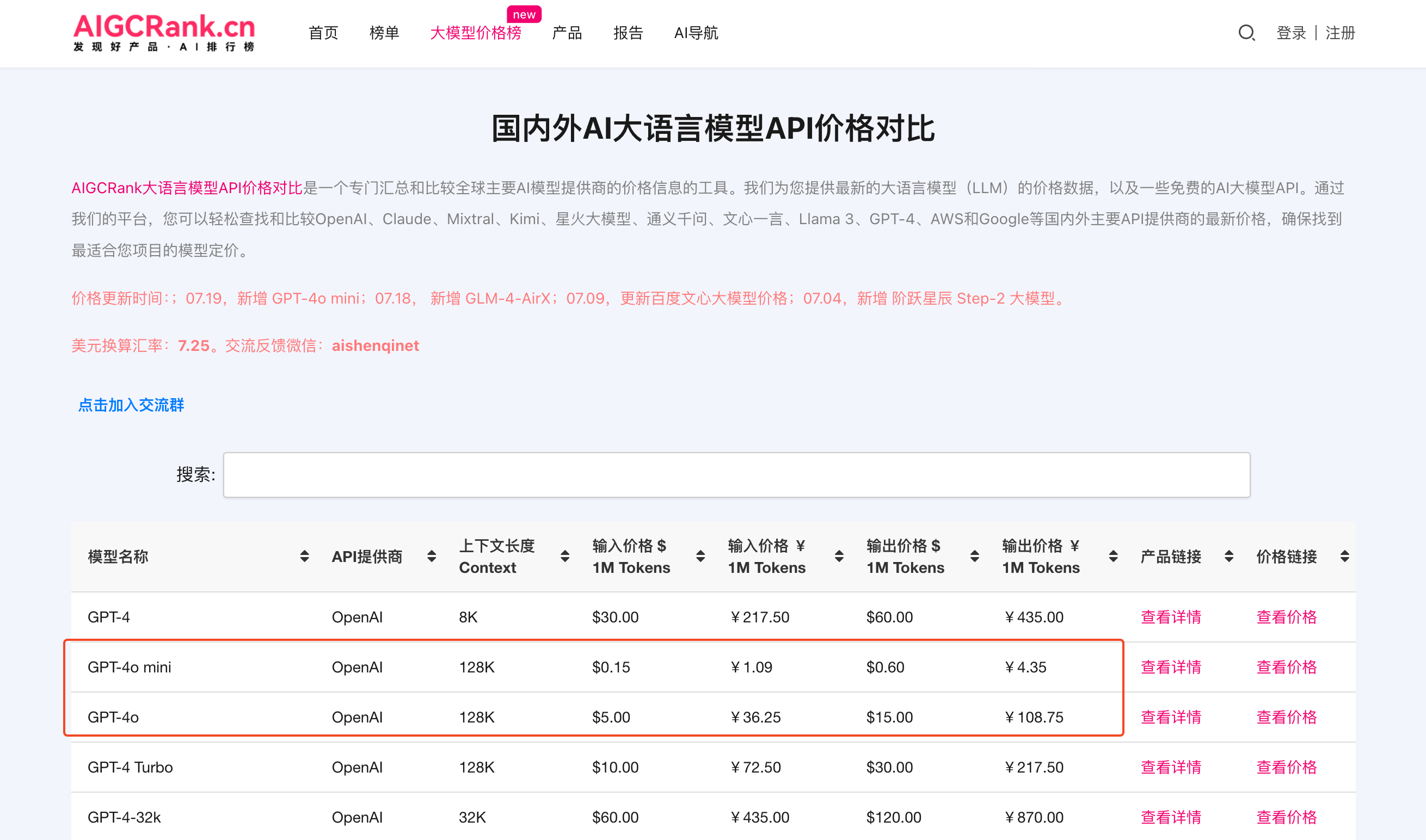
在确保性能满足需求的前提下,Claude 3 Haiku 「小」模型的成本优势,不言而喻。
被认为引起国内大模型集体降价的「始作俑者」DeepSeek(深度求索),在与 Gemini 1.5 Flash 综合表现相近的情况下,API 定价(每百万个)能做到输入 1 元、输出 2 元。阿里通义千问的 Qwen-Long,甚至还做到了输入 0.5 元、输出 2 元。
对于开发者而言,「成本」和「效益」是大模型应用中最核心的两点。而更低的大模型价格,无疑有助于更多企业和个人开发者在更多场景、更多应用中引入生成式 AI,也有助于 AI 在普通人生活、工作中的普及,正如 Oliver Parker 强调的:
我认为 GPT-4o Mini 真正体现了 OpenAI 让 AI 更加普及的使命。如果我们大家都希望 AI 惠及世界的每一个角落,每一个行业,每一个应用,我们一定要让 AI 更加实惠。
在今年 4 月举办的百度 AI 开发者大会上,李彦宏指出,在一些特定场景中,经过精调后的小模型,它的使用效果可以媲美大模型。

随后,阿里前技术副总裁贾扬清在朋友圈表示同意:「我觉得 Robin 这点说得非常对,在初始的应用尝试过去之后,模型的特化会是一个从效果上和从性价比上更加 make sense 的选择。」
「在整个网络上训练出来的巨型大语言模型可能会严重大材小用。」网络安全、内容分发和云计算公司 Akamai 的首席技术官 Robert Blumofe 表示,对公司来说,「你并不是特别需要一个知道《教父》所有演员、知道所有电影、知道所有电视节目的 AI 模型。」
简单来说,大模型在朝着「通用化」的方向走了太远,很多应用场景其实不需要大模型的「全能」。
而为了让每一个参数都变得更有价值,大模型厂商还在一直研究更高效的蒸馏、剪枝等模型压缩手段,试图将大型语言模型的「知识」,更多地迁移到更小、更简单的中小型语言模型中。

IEEE(电气电子工程师学会)旗下杂志《IEEE 综览》援引专业学者指出,大型语言模型直接采用互联网高度多样化的海量文本进行训练,但不管是微软的 Phi 模型,还是苹果 Apple Intelligent 中的模型,都是使用更丰富、更复杂的数据集来训练,具有更一致的风格和更高的质量,也更加容易学习。
打个比方,「大」模型相当于凭借着超高的记忆力和计算能力,在互联网这个充斥各种高质量、低质量的「大染缸」中学习;而现在的「小」模型则是直接学习经过筛选、提炼的「教课书」,自然更容易学进去。
不过有意思的是,去年的时候行业更多认为,「小」模型真正的用武之地是在设备端,诸如智能手机、笔记本电脑等计算设备中,但更多厂商和开发者在云端还是更重视「大」模型。
但在过去几个月,「小」模型还没有在设备端真正火起来,也开始成为云端的趋势所在。
究其根本,其实还是目前大模型在实际应用中「成本」与「效益」的不匹配,而「效益」还需要继续摸索、尝试的当下,「成本」就成了必须要解决的主要挑战。
在今年 4 月举办的 WIRED25(《连线 人)活动上,OpenAI CEO 山姆·奥特曼(Sam Altman)表示,大模型的进步不会来自模型的更大化,「我认为我们正处在巨大模型时代的终结。」

某种程度上,山姆·奥特曼暗示了酝酿已久的 GPT-5 不会在参数上继续扩大,而是通过算法或数据更进一步提升大模型的「智能」,从而通向 AGI(通用智能)。
至于刚刚推出的 GPT-4o mini,则是代表了另一条路径,一条将 AI 更快普及到全世界的路径。
但要走通这条路,最核心的问题是在确保「效益」的同时,尽可能地降低「成本」,让更多开发者用上 AI,用更具创意和实际价值的应用,让更多用户从中受益。
大模型加速落地,AI手机、AI PC、AI家电、AI搜索、AI电商……AI应用层出不穷;
7月流火,雷科技·年中回顾专题上线上半年值得记录的品牌、技术和产品,记录过去、展望未来,敬请关注。
